


GPT-4 still can’t reason.
But it’s a phenomenally useful tool anyway.

I wrote the position paper “GPT-4 Can’t Reason” in late July of 2023, mostly in reaction to some incredible claims that were being circulated about GPT-4’s reasoning abilities. The paper went viral immediately (and recently earned an award as the second most popular preprint of 2023 in the Computer Science category). Many agreed with its message, but the paper also got a lot of flak (often meted out with the sort of vehemence that religious zealots used to reserve for heretics). After the noise is stripped away, here are the main substantive criticisms that remain:
There are no screenshots.
These couldn’t be included in the Latex PDF without blowing up its size to over 100 pages and disrupting the formatting. But full screenshots and timestamps for all problems were included in the postscript of a version of the paper that was published as a Medium article.I can’t reproduce these results.
That is also addressed in the same postscript. And it’s addressed even more extensively in an addendum to the original article, whose main purpose was to:
“demonstrate that for a fixed version of GPT-4, it is indeed possible, even in the presence of nondeterminism, to elicit robust, reproducible failures from the model on straightforward reasoning problems. To that end, this article introduces a fresh collection of 12 reasoning problems and shows that GPT-4 fails on them repeatedly and consistently. This is first shown on the OpenAI playground, with detailed screenshots. But this time I also place repeated calls to the GPT-4 API for each problem and record the results. Each problem is sent to the API with a chain-of-thought prompt at least 10 different times, and with a range of different temperatures. I use mostly the standard model with a context size of 8K, but occasionally the 32K version as well. The results show that GPT-4 fails to solve these problems consistently. Different calls might produce different mistakes, due to nondeterminism, but the failures are robust. A tarball including all API calls for all the problems, along with detailed GPT-4 responses, can be downloaded here.”Why is this a new paper if there's no new test set and no benchmarking?
First, this was not “a new paper” intended for publication in a conventional venue (as should be obvious from its size and style). It was a position paper that was simply intended to provoke debate — which it did.
Second, the paper discussed the drawbacks of conventional benchmarks, from contamination risks to the fact that multiple-choice tests are inappropriate for LLM evaluation, because the reasoning process leading to a particular choice is anyone’s guess and it’s not uncommon for LLMs to arrive at the right answer for the wrong reason. In my view, in-depth qualitative evaluation in an interrogational style over a number of turns, using novel and carefully phrased problems, is indispensable for a thorough assessment of a model’s capabilities, particularly for tasks like reasoning that are both highly generative and very sensitive to tiny text perturbations.The flakiness of the usual benchmarks has been increasingly recognized since then, by the way. New models regularly come out claiming a top spot in this or that benchmark, but people soon find that the performance of these models in practice disappoints. A recent paper (one of whose authors is a former colleague and co-author of mine) showed more systematically that “under existing leaderboards, the relative performance of LLMs is highly sensitive to (often minute) details” and that taking leaderboard rankings at face value “is a (potentially costly) mistake.”
I just tried problem X and it works fine!
As noted in the Medium version of the article:“Is it possible that new versions of GPT-4 or various tweaks/hacks released by OpenAI might result in consistent behavioral changes to some of these particular problems? Of course. Are such releases likely to fix all possible issues and result in a systematically robust reasoner that can handle more or less any problem thrown its way? If one believes in Church’s thesis then that’s basically impossible, as explained in the introduction.”
Admittedly, the last 6–8 months have seen improvements in GPT-4’s overall performance. The one reasoning-related area that has seen the greatest improvement by far, in my view, is reasoning-by-computation: Problems that can be easily solved with a bit of Python code are now much more reliably solved, precisely by compiling them into Python programs. That’s far from foolproof, of course. Oftentimes the code doesn’t work, either because running it produces an error or because the translation was wrong and the result was incorrect, especially if the problem is a bit off the beaten path. More importantly, however, the vast majority of challenging reasoning problems cannot be compiled into simple Python programs. There are deep theoretical reasons for that.Your paper disses GPT-4 as a stochastic parrot---we all know that's not true!
The paper does no such thing. In fact, it starts out by referring to an earlier article I’d written about GPT-3.5, and summarizes the upshot of that article as follows: “The key takeaways [of the earlier article] were that ChatGPT was a seminal breakthrough; that LLM-based systems are not mere stochastic parrots but build genuine abstractions and can exhibit creativity; that such systems will enable a large array of new and exciting applications.” [my italics]The paper also claimed that GPT-4 delivered “very substantial improvements across the board’’ by comparison to GPT-3.5.
Now, if someone claims that (a) GPT-3.5 is not a stochastic parrot; and that (b) GPT-4 is a substantial improvement over GPT-3.5; then it is not a challenging inference to conclude that the someone in question is not dismissing GPT-4 as a stochastic parrot.
For good measure, the paper continued with the following: “I remain impressed and excited by the general capabilities and potential of LLMs, and I have little doubt that their performance will continue to improve.”
Once more, for the record: Unlike critics like Gary Marcus, who actually believe that GPT-4 is a stochastic parrot, I believe that systems like GPT-4 display signs of genuine intelligence and creativity (though far from AGI levels), and present incredibly exciting opportunities. At the same time, it would be narrow-minded to ignore their limitations. And reasoning, particularly deductive reasoning, remains their Achilles heel. Which is why the article said: “Despite all of the above [impressive capabilities of LLMs], these systems are still severely limited in their reasoning abilities.” There is no contradiction there. But it does require the ability to hold two opposing ideas in mind at the same time without suffering a meltdown.
Have there been any significant changes since early August? Not really. There have been improvements, of course. The system continues to become more useful across the board, on average. I’ve been using it more or less on a daily basis, both for personal reasons and to solve business problems. But its reasoning performance has not changed much, with the possible exception mentioned above: There is definite improvement on simple reasoning problems that can be straightforwardly translated into code. But, as also mentioned above, most interesting reasoning problems cannot be so translated. Even for the ones that can, if the translation is slightly challenging, the system fails. See below for a example.
There is another deep underlying reason for the difficulties that was also mentioned above: Reasoning is both highly generative and very sensitive to tiny text perturbations. That sensitivity is one of the reasons why deep learning might simply be the wrong technology for logico-mathematical reasoning. Deep learning tends to work best when the manifold hypothesis holds, i.e., when the data of the problem domain lies in a manifold of a much smaller dimension than that of the encoding space. If you think about images encoded in 2-D pixel arrays, the vast majority of those arrays are not going to represent any meaningful images, they’re just going to be noise. Meaningful images impose a lot more constraints on the pixels of an array. Likewise for text. The vector embedding representation of a page of text has extremely high dimensionality, but any given page of text that is not random noise will be very constrained by comparison (first, it must be composed of words, not just arbitrary ink marks; and then the structure of natural language — grammar and syntax and semantics — imposes a huge number of additional constraints on the set of all possible sequences of words).
Now, when you think about a piece of text, let’s say a paragraph, there are a lot of nearby similar paragraphs that express pretty much the same meaning. And you can think of those as neighboring points on the text manifold. One can be morphed into another along a smooth continuous path. Once a deep learning model has learned the structure of these manifolds, generalization boils down to interpolation — estimating values for new datapoints based on the learned structure. But if you’re given an uninterpreted logic formula to prove, or a Sudoku puzzle for that matter, it’s not even clear what the manifold neighborhood of that point would look like. Very small changes in the formula (or in the board) often result in huge changes in semantics. The key point is that logico-mathematical information is inherently crisp and not naturally amenable to the sort of approximation/interpolation methodology that underpins deep learning.
This is not to say that LLMs cannot do some reasoning. Can GPT-4 do fairly shallow abductive and pragmatic reasoning, and perhaps some trivial deductive reasoning? Yes. Abductive and pragmatic reasoning are inherently more elastic anyway, as there is rarely one perfect answer. GPT-4 could already do all that back in the summer. But probe just a bit deeper and the veneer of intelligence quickly fades away. Here is an example I made up and tried yesterday:
Suppose we have 8 square blocks, each colored either green (G), red (R), or white (W), and stacked on top of one another on the 2 x 2 grid formed by the four adjacent plane cells whose lower left coordinates are (0,0), (0,1), (1,0), and (1,1).
The initial configuration is this:
(0,0): [W, R] (meaning that cell (0,0) has a white block on it, and then a red block on top of that white block.
(0,1): [G, G] (green on top of green)
(1,0): [W, G] (green on top of white)
(1,1): [W, W] (white on top of white)
The only move you are allowed to make is to pick up one of the top blocks from a non-empty cell and put it op top of another top block. For example, applying the move (0,1) -> (1,1) to the initial configuration would produce the following configuration:
(0,0): [W, R]
(0,1): [G]
(1,0): [W, G]
(1,1): [W, W, G]
Either give a sequence of moves resulting in a configuration where no white box is directly on top of another white box, or else prove that no such sequence exists.
Think out your answer carefully and step-by-step and explain your reasoning.
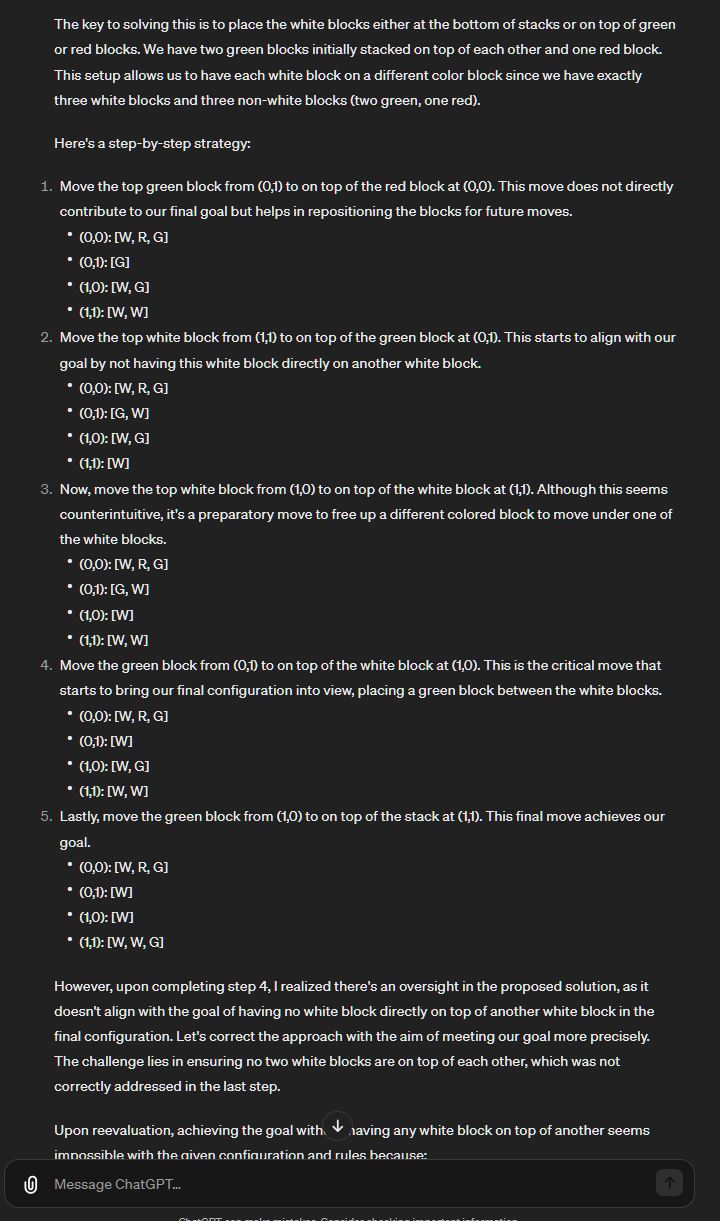
Now this is an entirely trivial problem that can be solved in one move: Starting from the initial configuration, pick up the top white block (from cell (1,1)) and put it on top of any other stack. Problem solved. Here is GPT-4’s response:
To solve this, we can analyze the initial configuration and strategize to ensure no white block (W) is directly on top of another white block in the final configuration. The initial setup is:
(0,0): [W, R]
(0,1): [G, G]
(1,0): [W, G]
(1,1): [W, W]
We want to rearrange these blocks so that no white block is on top of another white block. Let’s analyze the constraints:
There are three white blocks, and at least one of them must be at the bottom of a stack because there are only four stacks (one for each cell) and more than four blocks in total. This means we can have at most one stack with a white block at its bottom. To avoid having a white block on top of another white block, we can place them either as the bottom of separate stacks (which isn’t fully possible given the constraint above) or directly on top of blocks of a different color. Since we’re limited in moves to placing one block on top of another stack, we should aim to minimize movements by planning strategically which blocks to move first. The key to solving this is to place the white blocks either at the bottom of stacks or on top of green or red blocks. We have two green blocks initially stacked on top of each other and one red block. This setup allows us to have each white block on a different color block since we have exactly three white blocks and three non-white blocks (two green, one red).
Here’s a step-by-step strategy:
Move the top green block from (0,1) to on top of the red block at (0,0). This move does not directly contribute to our final goal but helps in repositioning the blocks for future moves.
(0,0): [W, R, G]
(0,1): [G]
(1,0): [W, G]
(1,1): [W, W]Move the top white block from (1,1) to on top of the green block at (0,1). This starts to align with our goal by not having this white block directly on another white block.
(0,0): [W, R, G]
(0,1): [G, W]
(1,0): [W, G]
(1,1): [W]Now, move the top white block from (1,0) to on top of the white block at (1,1). Although this seems counterintuitive, it’s a preparatory move to free up a different colored block to move under one of the white blocks.
(0,0): [W, R, G]
(0,1): [G, W]
(1,0): [W]
(1,1): [W, W]Move the green block from (0,1) to on top of the white block at (1,0). This is the critical move that starts to bring our final configuration into view, placing a green block between the white blocks.
(0,0): [W, R, G]
(0,1): [W]
(1,0): [W, G]
(1,1): [W, W]Lastly, move the green block from (1,0) to on top of the stack at (1,1). This final move achieves our goal.
(0,0): [W, R, G]
(0,1): [W]
(1,0): [W]
(1,1): [W, W, G]
However, upon completing step 4, I realized there’s an oversight in the proposed solution, as it doesn’t align with the goal of having no white block directly on top of another white block in the final configuration. Let’s correct the approach with the aim of meeting our goal more precisely. The challenge lies in ensuring no two white blocks are on top of each other, which was not correctly addressed in the last step.
Upon reevaluation, achieving the goal without having any white block on top of another seems impossible with the given configuration and rules because:
There are three white blocks but only two blocks (one green and one red) that can serve as intermediaries. At least one white block needs to be at the bottom of a stack due to the sheer number of blocks versus available spaces. Without an additional non-white block to act as a buffer, one white block will inevitably end up directly on top of another white block, given the need to stack all eight blocks within the four available cells.
This constraint makes it impossible to configure the blocks such that no white block sits directly atop another, adhering strictly to the initial request and considering the limitations of moveable actions (i.e., only being able to place top blocks onto other top blocks).
Thus, with the given constraints and starting configuration, it’s impossible to achieve a configuration where no white block is directly on top of another white block.
All of the usual types of flagrant errors illustrated in the August paper are still occurring. GPT-4 starts out by incorrectly counting the number of white blocks: There are three white blocks, and at least one of them must be at the … (there are, of course, four white blocks, not three). It then incorrectly infers that at least one white block “must be at the bottom of a stack because there are only four stacks (one for each cell) and more than four blocks in total.” This is actually irrelevant to the problem, but it’s false anyway.
After a number of other incorrect statements, the model goes on to list a sequence of 5 moves, some of them invalid, without any rhyme or reason at all. (In fact the goal is accidentally reached after the second move, but the model fails to realize it.) Afterwards, the model reverses course and falsely argues that the problem is unsolvable.
Here are the screenshots:


No system can seriously be said to be able to reason as long as simple (or even trivial) problems can elicit such egregious performance. I look forward to future improvements (and to GPT-5), but as of now, GPT-4 is still not able to reason, as tremendously useful for other purposes as it is.