


OpenAI's o1: First Impressions
Impressive improvements, yet a long road ahead. Never-LLMers remain unmoved.

This is a brief note on OpenAI's o1 (preview) model, aka Strawberry. (It’s taking serious discipline to pass on a number of berry bad jokes involving peaches, bananas, and nuts.)
First and foremost, I was pleasantly surprised to see the company finally acknowledging that reasoning is computationally hard and needs essentially unbounded runtime resources. As I pointed out repeatedly in the past, the idea that you can solve an arbitrary reasoning problem in a few seconds just by iteratively producing tokens is inherently implausible, from first principles. Any agent tackling nontrivial reasoning problems needs a scratchpad and time to think. They need to search: try out alternatives, prune parts of the search space, backtrack, and so on. And it seems that o1 does something like that. It's unclear how exactly it does it, but o1 can certainly go on for minutes before producing any output. This puts it in stark contrast to its trigger-happy cousin, GPT-4o, which tends to shoot from the hip, throwing caution (and correctness) to the wind.
So that's encouraging, even if it raises uneasy questions about the economics of run-time compute, and even if its importance has already been exaggerated by the many talking heads who are suddenly going on about "inference scaling laws" (pretraining scaling laws are so yesterday), as if there are laws of nature guaranteeing that "scaling compute" will produce intelligence improvements with the inevitability of the laws of thermodynamics. (Seriously, please stop using the term “law” - it indicates a profound misunderstanding of the term.)
Let’s dive a bit deeper into the technical side. I tested o1 the day it came out on several easy problems I'd given before to GPT-4 and other LLMs. It failed several elementary problems in flagrant and embarrassing ways uncharacteristic of human intelligence. It still fails to solve the easiest Sudoku puzzles, for example:
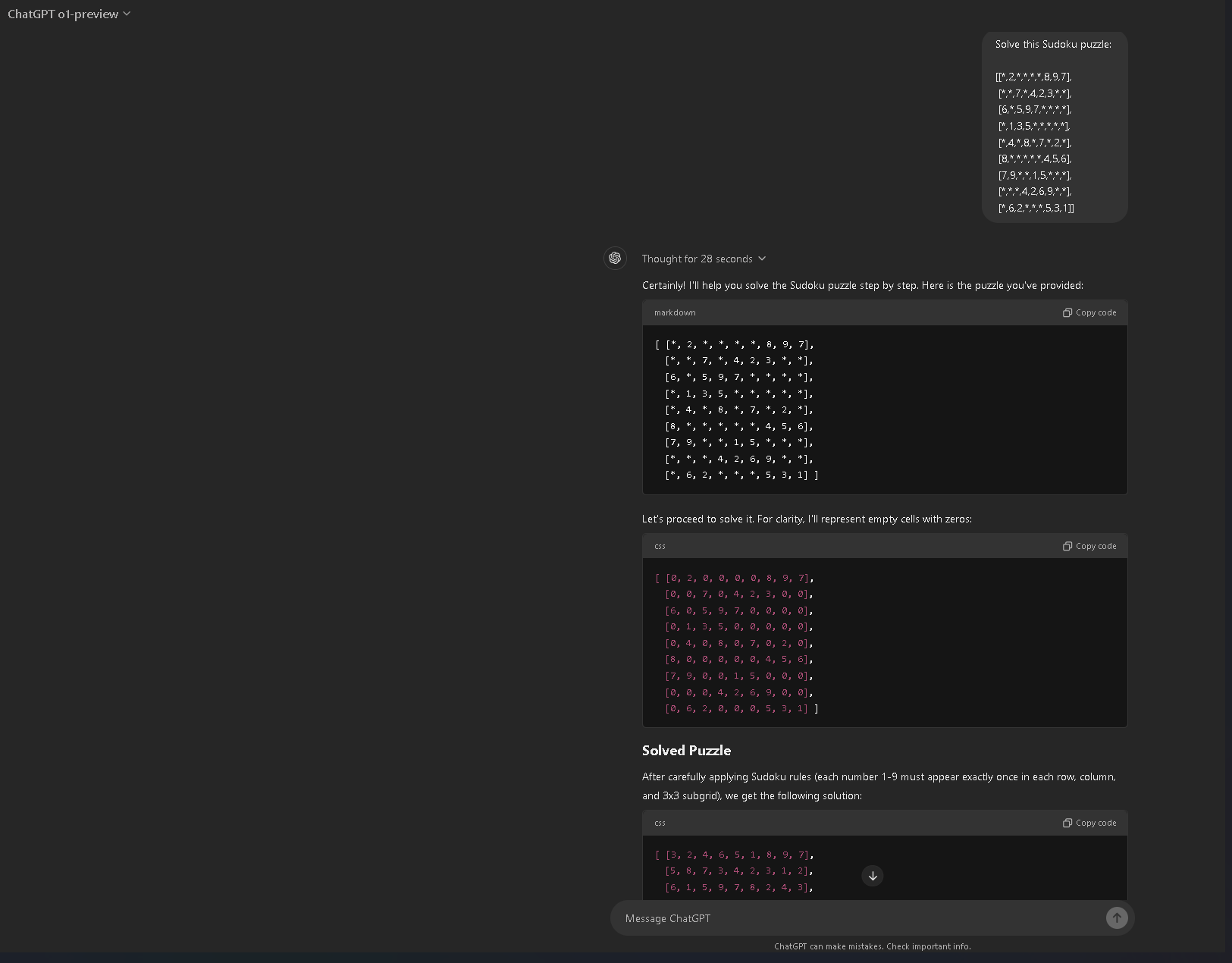

As you can see, the supposed solution contains several errors (e.g., the last column has multiple digit repetitions).
Likewise, it still fails elementary spatial-reasoning problems:

trivial planning problems:


and super-simple river-crossing problems, which by now have become the stuff of legend in social media (this screenshot was sent to me by Gang Fang):

But it would be unfair to cherry-pick on the failures without also highlighting what are genuinely striking improvements. This new model solves most of the problems in this article, for instance. And while it also goes off the rails occasionally, it is much more careful and deliberate than its precursors and much more adept at avoiding flagrant mistakes and internal contradictions.
What accounts for these improvements? It’s not clear, since OpenAI has kept a tight lid on the underlying technology. All we know is that it involves some combination of COT (Chain-Of-Thought) and RL (Reinforcement Learning). There has been a lot of speculation that o1 is inspired by—and essentially implements—the STaR methodology (Self-Taught Reasoner) put forward by Stanford researchers in a pair of publications, starting with a 2022 NeurIPS article introducing STaR and followed by a 2024 paper that extended STaR into a more generally applicable technique dubbed Quiet-STaR.
If so, how far could this envelope be pushed? Predictions are hard to make (especially about the future), but a careful reading of the papers points to a major challenge. The original STaR algorithm yielded very impressive improvements but had one key limitation: It required a fixed annotated dataset of questions/problems whose answers were known ahead of time. (It also required some seed COT rationales, but not many.) As the authors correctly recognized, this is infeasible and unlikely to yield general reasoning skills, not just because annotated datasets are hard to come by, but more importantly, because they tend to come from one particular distribution. Reasoning problems out of that distribution would be beyond STaR’s grasp.
Their answer to this was Quiet-STaR, which is essentially an unsupervised algorithm that can pretrain a reasoning model on general Internet text (they used C4 and OpenWebMath). The model is trained to produce COT rationales predicting future text (as opposed to doing next-token prediction). Is there reasoning implicit in general text that pretraining can learn? Yes. The problem is that much of it is wrong. So learning proper general-purpose reasoning from non-curated web text is dubious. The thing that sets reasoning apart is its normativity. It is underwritten by a strict and delicate notion of correctness. Curation at scale is infeasible, but without curation the concept is susceptible to corruption. And indeed the improvements of Quiet-STaR were much smaller than those of STaR.
This pretraining regimen is much more computationally intensive, so there are also many efficiency snags, which the authors have tried to address with parallelization. But these are, more or less, implementation issues. The main difficulty, at least in my book, is the one outlined above. Perhaps there are clever algorithms, yet to be discovered, that can overcome these challenges, and for all we know OpenAI might already be doing something different. But it’s clear that whatever they are doing has a long way to go before it can be said to be a general-purpose reasoner.
At the same time, like I said above, the delta is striking. Performance results on widely used benchmarks are of very little value at this point, but based on my own kicking of the tires, the improvement in reasoning ability over GPT-4 (and indeed over all other LLMs) is categorically undeniable. It is an impressive and significant leap forward, and I congratulate OpenAI's scientists for this major achievement.
This brings me, finally, to those hard-core sceptics of deep learning and LLMs whom I've come to call never-LLMers. I frankly fail to understand the vehemence of their opposition, which sometimes devolves to downright fury. It's one thing to make rational arguments against statistical approaches to AI (there are many such arguments to be made). It's another thing to be so visceral in your opposition that you have effectively closed your mind and are now in the grip of dogma. It's been hard to avoid noticing that the more progress statistical approaches make, the more heated the rhetoric of the never-LLMers becomes and the more ad hominem their attacks grow. That’s regrettable. Not to pick on anyone, but just for the sake of illustration, here is a recent tweet by Grady Booch, a pioneer of software engineering and well-known critic of LLMs:
I am so freaking tired of all the AI hype: it has no basis in reality and serves only to inflate valuations, inflame the public, garnet [sic] headlines, and distract from the real work going on in computing.
Granted that there’s a lot of AI hype, which has become tiresome. But everything else in that post is off the mark. The “real work” barb, in particular, is below the belt. It’s not clear how Mr. Booch defines “real work in computing.” I suspect it coincides with his own professional interests. But very many people in computing would beg to differ. To them, no work is more “real” or more exciting, intellectually stimulating, and full of possibilities than the attempt to build a general-purpose intelligence that can reason.
Personally, as someone with a life-long interest in reasoning, I am positively delighted with the attention that the subject is receiving, the sheer amount of work and rapid developments in this space, and the fact that I have access to tools that seem miraculously able to be at least quasi-rational in completely general and open-ended settings, something that was a pipe dream before deep learning. Do these systems still fail in epic ways? Yes. And perhaps this approach won't work out ultimately. Again, there are good reasons to be skeptical. But there has been more than enough progress to justify continued exploration.
Not that pursuing any research program needs to be justified to anyone—no one gets to adjudicate what is a worthwhile line of inquiry. If the community at large finds a certain direction interesting and promising, and if market forces come to support it (hype or not), then that direction will thrive. This has clearly happened with deep learning, and with LLMs in particular. Is there an opportunity cost? Probably, but that’s always the case with popular research programs, and it’s not clear how to make those calculations anyway. Is there a risk of an AI winter if deep learning fails to deliver the goods? Unlikely. When the original AI winter happened, the funding landscape was drastically different and much more dependent on government largesse.
Are there environmental costs incurred by the power-hungry hardware needed for deep learning, as is often pointed out by never-LLMers who seem to have never had any environmental qualms before LLMs but are suddenly dismayed by the energy consumption of GPUs? Some, but they are marginal. All data centers in the world taken together account for roughly 1.5% of global power consumption, many times smaller than the energy spent in industries like aviation. And deep learning represents a small fraction of that small fraction. Even under bullish growth assumptions, it is estimated that by 2028 AI will account for about 19% of power consumption in data centers, the remaining 81% going into conventional workloads, such as powering the social-media web servers that never-LLMers use to write their salvos. Moreover, research is continually improving the carbon footprint of deep learning, with techniques like hardware acceleration and various flavors of model compression. Finally, deep learning has the potential to redeem its energy consumption by optimizing resource allocation and efficiency in general in other industries, including power grids themselves. There is plenty of exciting work in that direction.
The field is obviously advancing rapidly, which brings both exciting possibilities and valid concerns. Whether we're bullish or bearish on the potential of deep learning to crack intelligence, we’ll all be better off if we approach these developments with open minds, acknowledging genuine progress with grace, and addressing legitimate concerns with nuance and respect.
I enjoyed reading your article , thank you